- Published on
I benchmarked OpenShift LightSpeed AI Assistant and this is what I found
- Authors

- Name
- Christophe Schmitz
TL;DR
The OpenShift LightSpeed AI Assistant is ridiculously useful. Even in its current tech preview phase, I’m already impressed. OpenShift admins and users are going to love it: the ability to ask general OpenShift question, generate YAML resources and demand, and more importantly, troubleshooting issue based on provided context (YAML, Logs, Events) is invaluable. For quick tests or lab environments, you can get it up and running in minutes by connecting it to OpenAI’s cloud models - gpt-4o mini works perfectly well. For disconnected clusters or environments where data can’t leave the premises, adding a GPU to your cluster and deploying a local LLM is the way to go, and it's easy. A well-trained 8-billion parameter conversational model is more than sufficient, and Granite 3.2-8B-Instruct is my top pick at the time of writing.
This benchmark will demonstrate the power of OpenShift LightSpeed, and demonstrate that a narrow LLM with 8 billions parameters is enough.
Table of Contents
Introduction
AI assistants are a powerful way to boost productivity. Yes, their answers still need cross-checking at times—but the pace of improvement is astonishing, and the productivity gains are already real.
In this post, I’ll share the results of a short, unbiased benchmark study that highlights how effective OpenShift LightSpeed (the OpenShift AI Assistant) can be in troubleshooting scenarios.
Why is this benchmark unbiased? Because I created a set of hands-on OpenShift troubleshooting exercises about a year ago, as a training asset for OpenShift users and admins. Now that LightSpeed is available, I’m using the exact same scenarios to evaluate its capabilities. No retrofitting or tailored prompts.
The benchmark compares results across three different LLM providers. LightSpeed itself needs an LLM backend, either cloud-hosted or self-managed, but thanks to its RAG (Retrieval-Augmented Generation) integration with OpenShift documentation, no model retraining or fine-tuning is needed.
Here are the models I used:
OpenAI gpt-4o-mini: Fast, powerful, affordable, and a leading option in the market. While OpenAI hasn’t disclosed the exact size of the model, it’s estimated to use ~8 billion parameters. It performed extremely well in this benchmark.
IBM Granite-3.2-8B-Instruct: Fully open source (beware of some other models that claimed to be open source, where it is actually not the case. Granite is truly Open Source) and indemnified, two characteristics that appeal to organizations running LLMs in their own data centers. At 8 billion parameters, this model is a solid peer to gpt-4o mini. In this benchmark, it was deployed on a GPU (Spoiler: it performs just as well.)
IBM Granite-3.2-2B-Instruct: At only 2 billion parameters, this model enters CPU-hosted territory. In my CPU tests, it's slow, too slow for a great user experience. But I included it (running on GPU) just to test whether small LLMs can still deliver good results (Spoiler: not yet). In this benchmark, it was deployed on a GPU.
What this benchmark is not:
Not a speed or concurrency test. Both Granite models ran on a single GPU and were fast enough for single-user usage.
Not a full LLM showdown. The goal is to showcase LightSpeed’s value even on smaller models in the 8B range, not rank every model on the market against OpenShift activities.
Not a comparison of LLM servers solutions. I used the open-source vLLM server, where Red Hat (via Neural Magic) is now the top contributor.
Not biased. All troubleshooting scenarios were written long before LightSpeed was released. Prompts were initially tested with gpt-4o mini, so it may have a slight edge—but identical prompts were used across all models.
Not covering all of LightSpeed’s capabilities. This post focuses on troubleshooting. While LightSpeed also answers general OpenShift questions and generates kubernetes YAML resources effectively, that’s outside the scope here.
Benchmark protocol
This benchmark is based on six troubleshooting exercises (or "tests") that I created over a year ago as part of a hands-on workshop to help OpenShift users learn how to diagnose and resolve issues. You can access the full workshop—including instructions, hints, and solutions—here: https://trbl-workshop.cszevaco.com/workshop.
With a good understanding of both how LightSpeed and OpenShift work, and as the original author of the workshop, I crafted a consistent set of questions to ask the AI assistant. The answers were assessed based on their accuracy and effectiveness in helping resolve the problem.
For this benchmark,
- I used OpenShift LightSpeed Operator in version 0.3.2, still in tech preview at time of writing. Running on OpenShift 4.18.5
- I used vLLM version: 0.8.4 with GPU support (event for Granite 3.2-2b model)
- The chat history was cleared between each test to avoid context issues.
The table below summarizes the six tests, the context provided (such as Kubernetes resource YAML, pod logs, and resource events), the prompts used, and the expected answers. Note that LightSpeed needs some context (YAML, logs...) to provide troubleshooting guidances specific to the problem at hand.
| Test | Problem statement | Context used | Prompt used | Expected results |
|---|---|---|---|---|
| 1 | The deployment specifies an incorrect image name, causing the pod to fail with ImagePullBackOff | Full Deployment YAML + full Pod YAML + Pod events | Why is the pod not starting? | The answer should highlight a possible typo in the image name, show the full image name, and mention other potential causes, while emphasizing the typo as a likely root cause. |
| There is a typo in the image name, what is the best approach to fix it? | The answer should recommend editing the deployment, not the pod, to demonstrate understanding of the deployment-pod relationship. | |||
| 2 | The container image has a typo in its entrypoint command (e.g., start vs. starttt), causing the pod to start and crash immediately. | Full Deployment YAML + full Pod YAML + full Pod log + Pod events | What's wrong? | The answer should identify the typo in the container’s entrypoint, recommend checking the script or command, and suggest rebuilding the image or updating the entrypoint to fix it. |
| I am not allowed to rebuild the container image. How can I fix the issue? | The answer should explain how to override the container’s command in the deployment specification to bypass the incorrect entrypoint without modifying the image. | |||
| 3 | The pod fails to start due to tight CPU and memory quotas in the namespace. Limits and requests must be tuned, but eventually, the deployment must be scaled down to one replica to fit within the quotas. | Full Deployment YAML | What's wrong? | The answer should identify resource quotas as the cause and suggest setting appropriate CPU and memory requests and limits for the containers. |
| Adding the namespace resource quotas | What value do you suggest I should use for the deployment limits and requests? | The answer should suggest resource values that fit within the quotas and ideally account for two replicas, or at least highlight the need to consider replica count when sizing limits and requests. | ||
| Since I am running two replicas in the deployment, what value do you suggest I should use? | The answer should clearly recommend CPU limits of 15m, memory limits of 15Mi, CPU requests of 10m, and memory requests of 7.5Mi. | |||
| Adding one failing Pod events + full Pod YAML + full Pod logs | Why is this pod not starting? | The answer should explain that the pod is failing due to out-of-memory (OOM) or resource exhaustion, suggest increasing the namespace resource quotas or optimizing container resource usage, and ideally recommend scaling down to one replica. | ||
| I can't optimize the application resources, and I can't change the resource quotas of the namespace. What are my other options? | The answer should suggest scaling down the deployment to one replica to fit within the existing resource quotas. | |||
| 4 | The route is unavailable due to two misconfigurations in the service: an incorrect pod selector and an invalid port mapping. | Full Deployment YAML + full Service YAML + full Route YAML | What is wrong with my route or service? | The answer should identify both the incorrect pod selector and the invalid service port configuration as the causes of the route being inaccessible. |
| 5 | The pod is unschedulable because the deployment specifies a node selector label that does not exist on any node. | Full Deployment YAML + full Pod YAML. | Why is the pod not deploying? | The answer should identify an issue with the node selector preventing pod scheduling and suggest reviewing or correcting the node selector configuration. |
| Adding one Node YAML | There is a policy that forces the use of node selector in the deployment definition. Based on the node definition attached, can you suggest some labels that are likely to be presents in all nodes, so that my pod can be scheduled everywhere? | The answer should provide a corrected node selector, ideally with clear instructions and an example shown in YAML format. | ||
| 6 | A namespace is stuck in terminating state due to lingering finalizers that have not been cleared. | Full Namespace YAML | Why is this namespace stuck in terminating? | The answer should mention that the namespace is stuck due to resources with lingering finalizers and should identify which resources are preventing termination. |
| Adding the full PVC YAML | Why is this PVC stuck in terminating state? | The answer should identify that a finalizer is blocking the PVC deletion and suggest checking the PVC’s owner reference or related resources. | ||
| Can you provide me with an openshift command line that identify any pod using this PVC? | The answer should provide an oc command to identify the pod(s) using the PVC or attached to the underlying PV. | |||
| Adding the full POD YAML | Why is this pod stuck in terminating state? | The answer should identify that a non-standard finalizer is blocking pod termination, and recommend removing the finalizer as part of the resolution. | ||
| How can I remove the finalizer? | The answer should provide an oc command to patch the resource and remove the finalizer. | |||
| Downloading the secret definition, and adding it via the upload option. | Why is this secret not deleted, and how can I delete it? | The answer should provide an oc command to patch the Secret and remove its finalizer, allowing the resource to be deleted. |
Out of the 6 tests mentioned above, many of my colleague were particularly impressed with test 4. That's the one you would want to dive a bit more first if needed.
The gif below illustrate the use of OpenShift LightSpeed to try and solve test 4.
Results
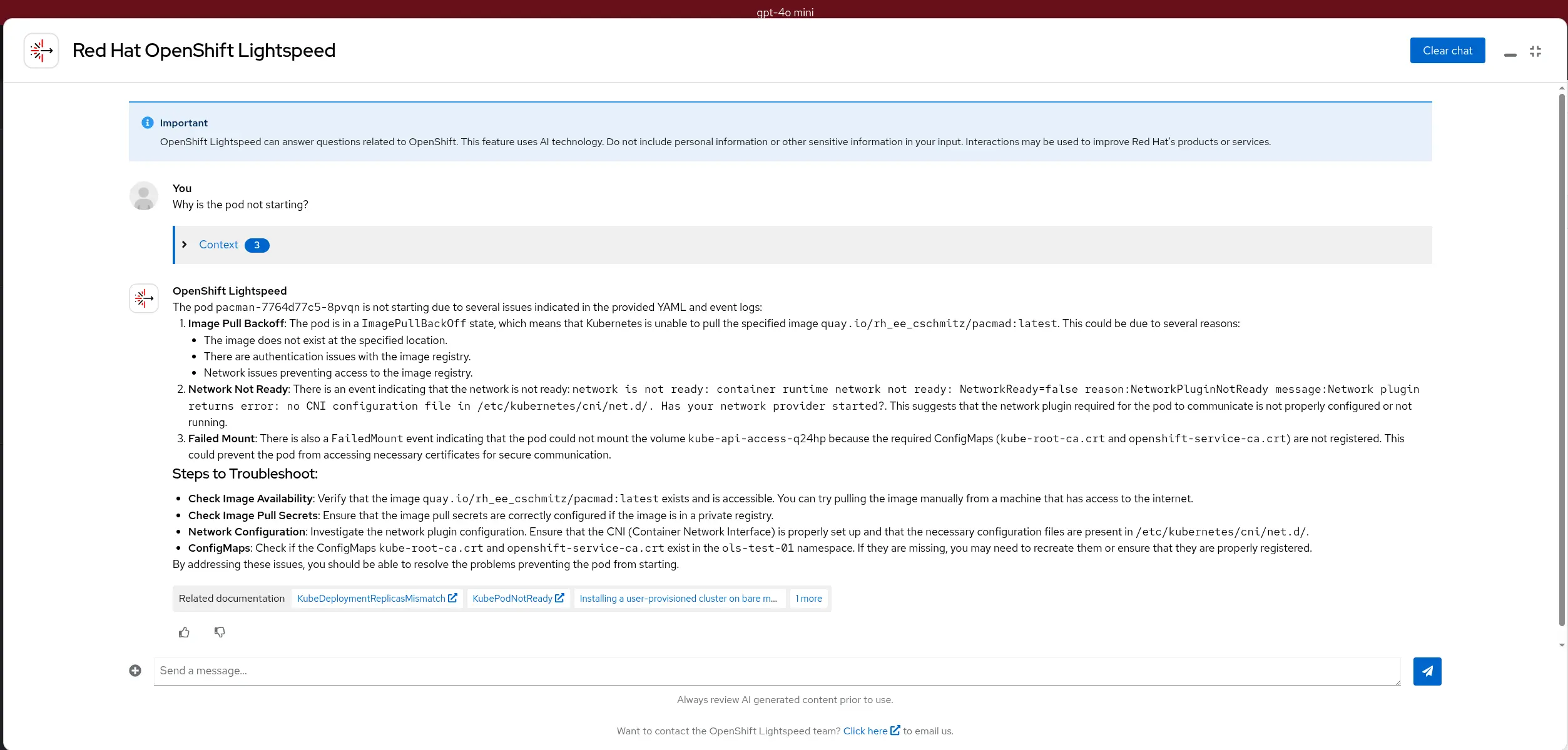
Test 1
Test 1 Summary problem statement
| Problem statement | Context used | Prompt used | Expected results |
|---|---|---|---|
| The deployment specifies an incorrect image name, causing the pod to fail with ImagePullBackOff | Full Deployment YAML + full Pod YAML + Pod events | Why is the pod not starting? | The answer should highlight a possible typo in the image name, show the full image name, and mention other potential causes, while emphasizing the typo as a likely root cause. |
| There is a typo in the image name, what is the best approach to fix it? | The answer should recommend editing the deployment, not the pod, to demonstrate understanding of the deployment-pod relationship. |
Test 1 Summary results
| Prompt used | Expected results | GPT-4o mini | Granite-3.2-8B-Instruct | Granite-3.2-2B-Instruct |
|---|---|---|---|---|
| Why is the pod not starting? | The answer should highlight a possible typo in the image name, show the full image name, and mention other potential causes, while emphasizing the typo as a likely root cause. | The answer provide a list of potential issues, including the actual existence of this specific "pacmad" image | The answer suggest, among other things, to verify that the image exists | The answer ask to check that the image is accessible, it doesn't directly suggest the image wouldn't exist |
| There is a typo in the image name, what is the best approach to fix it? | The answer should recommend editing the deployment, not the pod, to demonstrate understanding of the deployment-pod relationship. | The answer suggest to fix the deployment via a series of oc commands | The answer suggest to edit the yaml file (via the oc edit command). The very impressive bit is that it says: Assuming the correct image name is quay.io/.../pacman:latest Yes, it infered the correct name, very impressive. | The answer suggest to edit the yaml file, and provide an example assuming a fictitious image name |
Test 1 conclusion
gpt-4o-mini and granite3.2-8b and granite-3.2-2b all gave correct answers.
granite-3.2-8b was particularly impressive as it managed to infer the likely correct image name. Bonus point.
Test 1 Detailed results
Prompt 1
GPT-4o mini results
Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 2
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results
Test 2
Test 2 Summary problem statement
| Problem statement | Context used | Prompt used | Expected results |
|---|---|---|---|
| The container image has a typo in its entrypoint command (e.g., start vs. starttt), causing the pod to start and crash immediately. | Full Deployment YAML + full Pod YAML + full Pod log + Pod events | What's wrong? | The answer should identify the typo in the container’s entrypoint, recommend checking the script or command, and suggest rebuilding the image or updating the entrypoint to fix it. |
| I am not allowed to rebuild the container image. How can I fix the issue? | The answer should explain how to override the container’s command in the deployment specification to bypass the incorrect entrypoint without modifying the image. |
Test 2 Summary results
| Prompt used | Expected results | GPT-4o mini | Granite-3.2-8B-Instruct | Granite-3.2-2B-Instruct |
|---|---|---|---|---|
| What's wrong? | The answer should identify the typo in the container’s entrypoint, recommend checking the script or command, and suggest rebuilding the image or updating the entrypoint to fix it. | While an error in the NPM script is mentioned, a typo hasn't been suggested, and the wrong script "starttt" hasn't been mentioned | The message suggest to check that the "starttt" script actually exists | The answer suggest to check the "starttt" script actually exists, and suggest to use a "start" script if it is defined |
| I am not allowed to rebuild the container image. How can I fix the issue? | The answer should explain how to override the container’s command in the deployment specification to bypass the incorrect entrypoint without modifying the image. | The answer provide additional legitimate way to debug things, but does not provide the right solution | The answer correctly suggest to edit the deployment with a "command" section set to the start script | The answer suggest to rebuild the image, or mount a volume with the script, but does not provide the right answer |
Test 2 conclusion
On this test, only granite-3.2-8b managed to correctly solve this challenge. Now, I have to be honest, during my test and exploration, depending of the prompt used, or when using multiple prompts, it was always possible to guide gpt-4o-mini to the right answer, while it was a bit harder to get granite-3.2-2b to correctly edit the deployment (prompt 2). YMMV
Test 2 Detailed results
Prompt 1
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 2
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Test 3
Test 3 Summary problem statement
| Problem statement | Context used | Prompt used | Expected results |
|---|---|---|---|
| The pod fails to start due to tight CPU and memory quotas in the namespace. Limits and requests must be tuned, but eventually, the deployment must be scaled down to one replica to fit within the quotas. | Full Deployment YAML | What's wrong? | The answer should identify resource quotas as the cause and suggest setting appropriate CPU and memory requests and limits for the containers. |
| Adding the namespace resource quotas | What value do you suggest I should use for the deployment limits and requests? | The answer should suggest resource values that fit within the quotas and ideally account for two replicas, or at least highlight the need to consider replica count when sizing limits and requests. | |
| Since I am running two replicas in the deployment, what value do you suggest I should use? | The answer should clearly recommend CPU limits of 15m, memory limits of 15Mi, CPU requests of 10m, and memory requests of 7.5Mi. | ||
| Adding one failing Pod events + full Pod YAML + full Pod logs | Why is this pod not starting? | The answer should explain that the pod is failing due to out-of-memory (OOM) or resource exhaustion, suggest increasing the namespace resource quotas or optimizing container resource usage, and ideally recommend scaling down to one replica. | |
| I can't optimize the application resources, and I can't change the resource quotas of the namespace. What are my other options? | The answer should suggest scaling down the deployment to one replica to fit within the existing resource quotas. |
Test 3 Summary results
| Prompt used | Expected results | GPT-4o mini | Granite-3.2-8B-Instruct | Granite-3.2-2B-Instruct |
|---|---|---|---|---|
| What's wrong? | The answer should identify resource quotas as the cause and suggest setting appropriate CPU and memory requests and limits for the containers | Resource quotas, and lack of cpu/memory limits/requests is identified, suggesting to edit the deployment | Resource quotas, and lack of cpu/memory limits/requests is identified, suggesting to edit the deployment | A problem in CPU resource is identified, but not in light of resource quotas. In addition, it suggest to directly edit the pod, instead of the deployment |
| What value do you suggest I should use for the deployment limits and requests? | The answer should suggest resource values that fit within the quotas and ideally account for two replicas, or at least highlight the need to consider replica count when sizing limits and requests.. | It suggests to use value in light of the quota, but does not spontaneously take into account the two replicas | It suggests to use value in light of the quota, but does not spontaneously take into account the two replicas | It suggests to use value in light of the quota, but does not spontaneously take into account the two replicas. Besides, it show a YAML example of the ResourceQuota resource, instead of the deployment |
| Since I am running two replicas in the deployment, what value do you suggest I should use? | The answer should clearly recommend CPU limits of 15m, memory limits of 15Mi, CPU requests of 10m, and memory requests of 7.5Mi.. | The answer is correctly dividing the limits and requests by two, and provide a deployment example | The answer is correctly dividing the limits and requests by two, and provide a deployment example | The answer is still focusing on editing the resourcequota, instead of the deployment |
| Why is this pod not starting? | The answer should explain that the pod is failing due to out-of-memory (OOM) or resource exhaustion, suggest increasing the namespace resource quotas or optimizing container resource usage, and ideally recommend scaling down to one replica. | A memory issue is identified, and it is suggested to increase the limits, or optimize the application. | A memory issue is identified, and it is suggested to increase the limits, or optimize the application. | A memory issue is identified, and it is suggested to increase the limits, or optimize the application. |
| I can't optimize the application resources, and I can't change the resource quotas of the namespace. What are my other options? | The answer should suggest scaling down the deployment to one replica to fit within the existing resource quotas. | Scaling down is not suggested | Scaling down is not suggested | Scaling down is not suggested |
Test 3 conclusion
This test is more challenging, requires multiple prompts with the AI assistant, and the last prompt didn't led to the correct answer. However, I know that during my investigation, I got several time the correct answer, scaling down the replica was suggested. This only highlight the sensitivity of the answer based on slightly different prompt, or context.
Test 3 Detailed results
Prompt 1
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 2
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 3
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 4
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 5
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Test 4
Test 4 Summary problem statement
| Problem statement | Context used | Prompt used | Expected results |
|---|---|---|---|
| The route is unavailable due to two misconfigurations in the service: an incorrect pod selector and an invalid port mapping. | Full Deployment YAML + full Service YAML + full Route YAML | What is wrong with my route or service? | The answer should identify both the incorrect pod selector and the invalid service port configuration as the causes of the route being inaccessible. |
Test 4 Summary results
| Prompt used | Expected results | GPT-4o mini | Granite-3.2-8B-Instruct | Granite-3.2-2B-Instruct |
|---|---|---|---|---|
| What is wrong with my route or service? | The answer should identify both the incorrect pod selector and the invalid service port configuration as the causes of the route being inaccessible. | The pod selector mismatch, and the port configuration issue are both detected, and an updated yaml resource is suggested. | The pod selector mismatch, and the port configuration issue are both detected | The answer is only focusing on the port mismatch, and in a desorganized way |
Test 4 conclusion
To me, and many colleague, the result of this test are very impressive, as it detected multiple problems at one. gpt-4o-mini got some extra points as it immediatly suggested some fixes in the service yaml. It would require an extra prompt to get granite-3.2-8b to provide the YAML. granite-3.2-2b is laking a bit of reasoning power, and this was a general observation when experimenting with test 4 and granite-3.2-2b.
Test 4 Detailed results
Prompt 1
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Test 5
Test 5 Summary problem statement
| Problem statement | Context used | Prompt used | Expected results |
|---|---|---|---|
| The pod is unschedulable because the deployment specifies a node selector label that does not exist on any node. | Full Deployment YAML + full Pod YAML. | Why is the pod not deploying? | The answer should identify an issue with the node selector preventing pod scheduling and suggest reviewing or correcting the node selector configuration. |
| Adding one Node YAML | There is a policy that forces the use of node selector in the deployment definition. Based on the node definition attached, can you suggest some labels that are likely to be presents in all nodes, so that my pod can be scheduled everywhere? | The answer should provide a corrected node selector, ideally with clear instructions and an example shown in YAML format. |
Test 5 Summary results
| Prompt used | Expected results | GPT-4o mini | Granite-3.2-8B-Instruct | Granite-3.2-2B-Instruct |
|---|---|---|---|---|
| Why is the pod not deploying? | The answer should identify an issue with the node selector preventing pod scheduling and suggest reviewing or correcting the node selector configuration | The node selector is mentioned as a potential issues, among other things | The node selector is mentioned as a potential issues, among other things | The node selector is mentioned as a potential issues, among other things |
| There is a policy that forces the use of node selector in the deployment definition. Based on the node definition attached, can you suggest some labels that are likely to be presents in all nodes, so that my pod can be scheduled everywhere? | The answer should provide a corrected node selector, ideally with clear instructions and an example shown in YAML format. | A list of sensible labels are suggested for the node selector | A list of sensible labels are suggested for the node selector | A list of sensible labels are suggested for the node selector |
Test 5 conclusion
All models performed correctly against this test.
Test 5 Detailed results
Prompt 1
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 2
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Test 6
Test 6 Summary problem statement
| Problem statement | Context used | Prompt used | Expected results |
|---|---|---|---|
| A namespace is stuck in terminating state due to lingering finalizers that have not been cleared. | Full Namespace YAML | Why is this namespace stuck in terminating? | The answer should mention that the namespace is stuck due to resources with lingering finalizers and should identify which resources are preventing termination. |
| Adding the full PVC YAML | Why is this PVC stuck in terminating state? | The answer should identify that a finalizer is blocking the PVC deletion and suggest checking the PVC’s owner reference or related resources. | |
| Can you provide me with an openshift command line that identify any pod using this PVC? | The answer should provide an oc command to identify the pod(s) using the PVC or attached to the underlying PV. | ||
| Adding the full POD YAML | Why is this pod stuck in terminating state? | The answer should identify that a non-standard finalizer is blocking pod termination, and recommend removing the finalizer as part of the resolution. | |
| How can I remove the finalizer? | The answer should provide an oc command to patch the resource and remove the finalizer. | ||
| Downloading the secret definition, and adding it via the upload option. | Why is this secret not deleted, and how can I delete it? | The answer should provide an oc command to patch the Secret and remove its finalizer, allowing the resource to be deleted. |
Test 6 Summary results
| Prompt used | Expected results | GPT-4o mini | Granite-3.2-8B-Instruct | Granite-3.2-2B-Instruct |
|---|---|---|---|---|
| Why is this namespace stuck in terminating? | The answer should mention that the namespace is stuck due to resources with lingering finalizers and should identify which resources are preventing termination. | The answer list the dangling resources, along with their finalizer, and suggest to remove those finalizer | The answer list the dangling resources, along with their finalizer, and suggest to remove those finalizer | The answer list the dangling resources, along with their finalizer, and suggest to remove those finalizer |
| Why is this PVC stuck in terminating state? | The answer should identify that a finalizer is blocking the PVC deletion and suggest checking the PVC’s owner reference or related resources. | The answer explains why there is still a finalizer on the PVC, suggest to check the status of the associated PV, and provides instruction to remove the finalizer if it's safe to do so | The answer explains why there is still a finalizer on the PVC, and provides instruction on how to remove it. However, it does not provide any hint that one should check if the PVC is still being used. | The answer explains why there is still a finalizer on the PVC, suggest to delete the finalizer, and also suggest to check for resources that are still using the PVC |
| Can you provide me with an openshift command line that identify any pod using this PVC? | The answer should provide an oc command to identify the pod(s) using the PVC or attached to the underlying PV. | The oc command provided works as intended | The oc command did not work, potentially due to this known issue | The oc command did not work |
| Why is this pod stuck in terminating state? | The answer should identify that a non-standard finalizer is blocking pod termination, and recommend removing the finalizer as part of the resolution. | The answer correctly identify the non-standard finalizer, and suggest to remove it with an oc edit command | The answer correctly identify the non-standard finalizer, and suggest to remove it with an oc patch command, which is more convenient | The issue with the finalizer is not identified |
| How can I remove the finalizer? | The answer should provide an oc command to patch the resource and remove the finalizer. | An oc edit command with instructions is provided | A more convenient oc patch command is provided | Generic instructions with oc patch is provided for pvc or pod. However, I would expect the instruction to focus on pod, and use the specific pod name, instead of a generic name |
| Why is this secret not deleted, and how can I delete it? | The answer should provide an oc command to patch the Secret and remove its finalizer, allowing the resource to be deleted. | oc edit command instructions for the secret is provided | oc patch command instructions for the secret is provided | oc patch command instructions for the secret is provided |
Test 6 conclusion
gpt4o-mini succesfully answered all prompts. grantie-3.2-8b had an issue with the oc commands, probably due to a known issue. However, the oc command suggested was more complex that needed. As usual, prompting differently yield different results, YMMV. granite-3.2-2b just doesn't have the reasoning capabilities for these challenge, and it would take several prompt attempt to get to the right answer.
Test 6 Detailed results
Prompt 1
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 2
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 3
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 4
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 5
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Prompt 6
GPT-4o mini results

Granite-3.2-8B-Instruct results

Granite-3.2-2B-Instruct results

Conclusion
This benchmark highlights several key insights:
OpenShift LightSpeed is already a powerful assistant for OpenShift users, even in its current tech preview state. While the underlying LLM isn’t trained specifically on OpenShift, it uses Retrieval-Augmented Generation (RAG) to tap into embedded OpenShift documentation, making it remarkably context-aware.
A self-hosted 8Billions parameter model, like Granite 3.x, offers strong reasoning capabilities and is more than sufficient for organizations that can’t use cloud-hosted LLMs due to compliance or disconnected environments. These models fit comfortably on high-end consumer GPUs or entry-level enterprise GPUs. However, remember that memory sizing must also account for context window and concurrency requirements.
Smaller models (e.g., 2B parameters) are probably not reliable enough at this stage for effective troubleshooting, though rapid advances in the AI space may change this soon.
Prompting still requires experience. As with most LLM-based tools, phrasing matters. Results vary depending on how questions are asked. That said, both GPT-4o-mini and Granite-3.2-8B consistently allowed LightSpeed to be steered toward useful, actionable answers.