- Published on
Accessing a private OpenShift cluster from anywhere with Tailscale VPN
- Authors

- Name
- Christophe Schmitz
Disclaimer: I had no idea how to use Tailscale VPN 2 days ago. It's ridiculously easy!
TL;DR
Tailscale and it's open source counterpart Headscale are becoming incredibly popular as a zero config VPN solution. Its NAT transversal capability make it incredibly easy to established a secured connection between two machines, even when both are behind a NAT / firewall. Tailscale released last year a kubernetes operator that make it easy to install and configure on your kubernetes cluster. However, there are a couple of fixes needed to make it OpenShift compatible out of the box. Until Tailscale implement those small changes, a couple of hacks are required. I didn't find some satisfactory blog or documentation that tackle this, I thought this blog post would help the OpenShift community.
At the end of this blog post, you should be able to deploy tailscale, and have access to the api, as well as the OpenShift console. You will also be able to expose other services inside your cluster, to your tailscale network.
Table of Contents
Seting up Tailscale
Create an account / tailscale network
You will need to create a tailscale network, attached to an account. I Signed up with my personal google account.
Then there should be some instructions to install tailscale on your first machine, your current laptop is a good place to start.
Just follow those steps. Once you have access to the tailscale console, you will need to complete two kubernetes prerequisites, as explained here: https://tailscale.com/kb/1236/kubernetes-operator#prerequisites :
- Configure some kubernetes ACL tags, this link should bring you to the right location in the tailscale admin console: https://login.tailscale.com/admin/acls/file In the doc, they omit the required comma
,at the end, make sure you add it:

- Configure an oauth client, and get a client ID / Secret. This link should bring you to the right place. https://login.tailscale.com/admin/settings/oauth Store the clientID / secret somewhere, you will need it later.
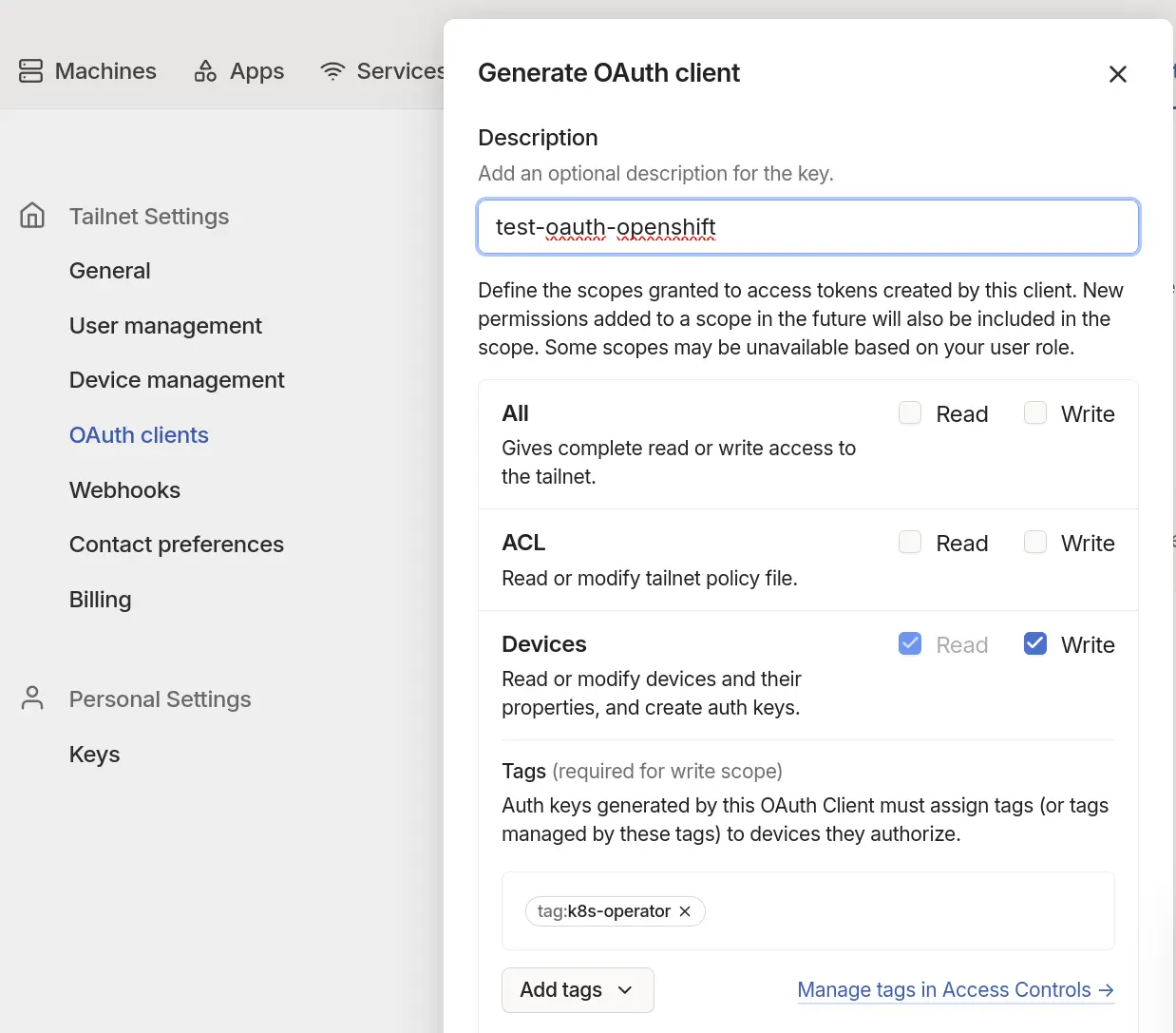
Tailscale operator for kubernetes
There is an operator deployable via helm. Finger crossed this operator will eventually find its way in the OpenShift Operator Hub. For the time being, a manual helm install is required. At the time of writing, the container image of that Operator (v1.70.0) doesn't meet the OpenShift security requirement, and a small hack is required. Let's get started.
This section documentation gives you some indication on how to install the operator with helm. https://tailscale.com/kb/1236/kubernetes-operator#helm
Unless it’s fixed, chances are the operator won’t deploy nicely without a hack. I am on version 1.70.0 of the chart.
cschmitz@fedora:~$ helm search repo tailscale
NAME CHART VERSION APP VERSION DESCRIPTION
tailscale/tailscale-operator 1.70.0 v1.70.0 A Helm chart for Tailscale Kubernetes operator
and when the operator is deployed with the helm upgrade .... command, chances are the pod will crashloop
with an error in the container log that would look like:
mkdir /.config: permission denied
This kind of issue is typical of running container images that don’t follow OpenShift best security practices. Those practices are explained in this Red Hat best practices for building images article So really, all that is needed is to precreate this /.config directory, and run the chown / chmod commands explained in the article. Hopefully Tailscale will eventually implement this, but for the time being, a small hack is required. I went with the option of rebuilding the image implementing Red Hat best security practice:
Workaround #1
Rebuild your own operator image with something like
FROM tailscale/k8s-operator:v1.70.0
RUN mkdir /.config
RUN chgrp -R 0 /.config && \
chmod -R g=u /.config
USER 1001
And push it to a container registry. If you trust me (should you?), you could use mine: quay.io/rh_ee_cschmitz/tailscale-ocp-k8s-operator:v1.70.0 but really, don’t use my image, who knows what’s inside apart for me? Besides, mine is for v1.70.0, and the Tailscale project is moving quickly...
Using that modified image with the helm chart is quite simple, it just needs two extra arg to overwrite the image repo and image tag (adjust with your image / tag of course, unless you trust me):
helm upgrade \
--install \
tailscale-operator \
tailscale/tailscale-operator \
--namespace=tailscale \
--create-namespace \
--set-string oauth.clientId=<OAauth client ID> \
--set-string oauth.clientSecret=<OAuth client secret> \
--set-string operatorConfig.image.repository=quay.io/rh_ee_cschmitz/tailscale-ocp-k8s-operator \
--set-string operatorConfig.image.tag=v1.70.0 \
--wait
The operator should deploy fine now, and you should see a new tailscale-operator "machine" in the tailscale console:
Using the Tailscale operator.
Once the operator is installed, there are several ways you can use it. In my case, I want three things:
- Have access to the console
- have access to any route exposed, and
- have access to the API.
Let's see how to achieve that.
Accessing the OpenShift console by exposing it's service
It's done quite simply by adding a tailscale annotation into the service. There is a second hack required to get it to work on OpenShift, but first, let's try without. The OpenShift console service is in the openshift-console namespace. Adding the required tailscale annotation tailscale.com/expose=true can be done via the command line with:
oc annotate service console tailscale.com/expose=true -n openshift-console
Unless it's fixed to work on OpenShift, chances are the statefullset that the Tailscale operator is going to deploy (after adding the annotations) will crashloop-backoff
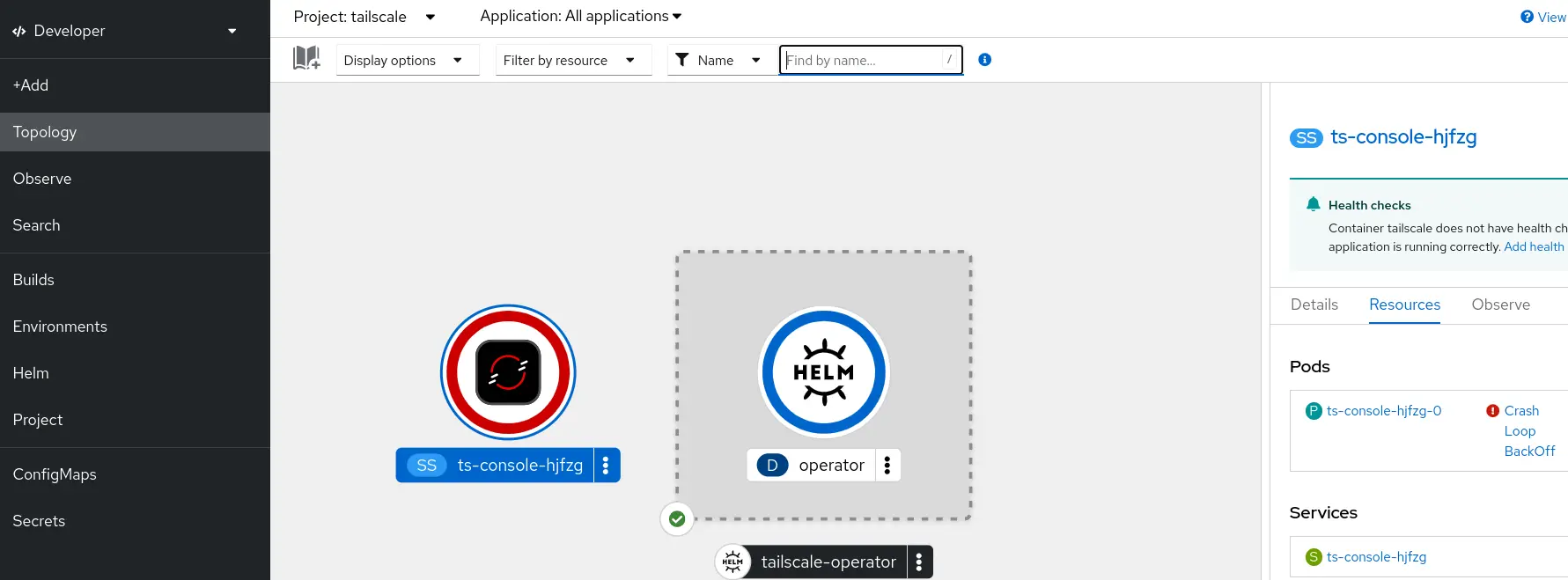
And the container log this time indicate:
Unable to create tuntap device file: operation not permitted
This github issue https://github.com/tailscale/tailscale/issues/10814 indicates that the current workaround is to run the tailscale operator container with privileged mode. I am pretty sure there should be some more restrictive mode than the blank privileged mode, but for the time being I'll go with that. To achieve this, we need to create a tailscale proxyClass that let's us overide some of the containers settings. Create a ocp-proxyclass.yaml file with
Workaround #2
Until tailscale fixes the issue, run the container in privileged mode using a proxy class.
apiVersion: tailscale.com/v1alpha1
kind: ProxyClass
metadata:
name: ocp
spec:
statefulSet:
pod:
tailscaleInitContainer:
securityContext:
privileged: true
tailscaleContainer:
securityContext:
privileged: true
Note that proxyclass is not namespaced Then
oc apply -f ocp-proxyclass.yaml
We need to add a label (not an annotation) to the service to specify the proxyclass to use:
oc label service console tailscale.com/proxy-class=ocp -n openshift-console
And of course, we need to add the privileged securityContextConstraints to the service account used by the pod: proxies. This is done with:
oc adm policy add-scc-to-user privileged -z proxies -n tailscale
It may be required to delete the statfulset associated with the service, and let it be recreated by the operator, in order to pick up the proxy class correctly. If everything goes well:
- the pod should now be running,
- you should see a new machine in the Tailscale admin console
Now, in theory, you could try and use the tailscale magicDNS to connect to the console. In practice, OpenShift console route is running via the HA proxy and is expecting to receive https requests to a host named ... https://console-openshift-console.apps.your-cluster-domain Anything else and it won't be routed to the service.
Next, you could try to add some DNS entry somewhere to resolve console-openshift-console.apps.your-cluster-domain to the tailscale IP address of the openshift-console-console machine. This will work, and when connecting to the OpenShift console for the first time, OpenShift will want to authenticate you with it's openshift-authentication service / route oauth-openshift.apps.your-cluster-domain The next step would be to expose that service to Tailscale, and make sure the route resolve to the tailscale machine IP of that service. That works, but at this stage there are two inconvenient:
- ssl termination on those OpenShift routes doesn't happen at the service level, it happens at the ha-proxy level. So my let's encrypt certificate is not in use, and the certificate is not trusted.
- I would need to maintain some dns entry for every service I expose (console, oauth, and more), and annoyingly, each service would get a different machine IP on tailscale. This adds some burden to maintain some dns entry somewhere.
So instead, a more drastic solution, which works fine for home lab setups, is just to expose the OpenShift ha-proxy service on tailscale. Let's see that in action in the next section
Accessing any OpenShift route (including console, oauth)
Unless Tailscale has fixed this issue, make sure to follow the previous section to add and use a proxyclass, and configure the proxies service account securityContextConstraints.
The openshift-ingress namespace contains the router-internal-default service. By exposing this service to tailscale, all the OpenShift routes will be accessible. Let's give it a try.
oc label service router-internal-default tailscale.com/proxy-class=ocp -n openshift-ingress
oc annotate service router-internal-default tailscale.com/expose=true -n openshift-ingress
After that, the tailscale admin console will display a new machine for the router-internal-default service. You can then resolve *.apps.your-cluster-domain to this unique machine / ip address. One option is to use /etc/hosts, but it doens't support wildcard, so you will need to add each entry (console, oauth, argocd etc...) independently, albeit against the same IP address. If you own the domain you are using, you can also use the dns service with a wildcard domain, albeit you will have to potentially wait for dns propagation when things change. Maybe the best option is to configure something like dnsmasq on your laptop, to efficiently resolve the wildcard domain you used, against the tailscale IP address of the router-internal-default service. That's the option I went for, and that solves all my requirements. Because tls termination happens at the right place, my certificate is correctly used, no issue there neither.
Final step, getting access to the kubernetes API...
Accessing the kubernetes API.
This is quite easy, all is needed is an extra flag for the helm deployment. I picked the noauth one as I am using oc login commands to authenticate / authorize. Tailscale instructions are here: https://tailscale.com/kb/1437/kubernetes-operator-api-server-proxy#configuring-api-server-proxy-in-noauth-mode
helm upgrade \
--install \
tailscale-operator \
tailscale/tailscale-operator \
--namespace=tailscale \
--create-namespace \
--set-string oauth.clientId=<OAauth client ID> \
--set-string oauth.clientSecret=<OAuth client secret> \
--set-string operatorConfig.image.repository=quay.io/rh_ee_cschmitz/tailscale-ocp-k8s-operator \
--set-string operatorConfig.image.tag=v1.70.0 \
--set-string apiServerProxyConfig.mode="noauth"
--wait
Once this is done, the Tailscale operator pod will restart, it contains the api proxy activated by the previous command. Connecting to it requires:
- the magicDNS of that machine, available via the tailscale web console
- that's it, I didn't need bullet points.
Something like below should work. Enjoy.
oc login --web https://tailscale-operator.tailabcde.ts.net:443
Conclusion
Tailscale is not that far away from working out of the box on OpenShift. It just needs a small update in the Containerfile used to build the image, and a better handling of securityContextConstraints / privileged mode. The workaround #1 and #2 should get you started however, until those fixes are implemented.